
Ocena ryzyka w fazie projektowania apki

Wprowadzenie do tematu
Za każdym razem, kiedy myślimy o RODO, myślimy o papierkologii. W tym odcinku pokażę Ci, że czasami jest to całkowicie omylne spojrzenie na przepisy prawa.
RODO skoncentrowane jest na ochronie interesu jednostek, np. użytkowników aplikacji, którą tworzy Twój startup. Wobec tego, przepisy wymagają od startupu, aby zbadał potencjalne ryzyko związane z przetwarzaniem przez taką aplikację danych osobowych użytkowników.
W celu weryfikacji, jakie jest ryzyko przetwarzania danych, RODO podsuwa nam dwa narzędzia:
1) OGÓLNĄ ANALIZĘ RYZYKA przetwarzania danych
2) OCENĘ SKUTKÓW przetwarzania dla ochrony danych (tzw. DPIA).
Ogólna analiza ryzyka oraz DPIA to procesy analizy naszego postępowania z danymi, które mają nam pomóc wyłonić najwłaściwsze środki bezpieczeństwa. Każdą z tych analiz zawsze wykonujemy więc po coś namacalnego - żeby znaleźć rozwiązania zabezpieczające dane w sposób najbardziej adekwatny według wyniku analizy. Adekwatny to znaczy ograniczający wybadane zawczasu ryzyko.
Ogólna analiza ryzyka różni się zasadniczo od DPIA tym, że obowiązuje każdego administratora. Bez względu na wielkość czy zakres działalności - każdy kto dane przetwarza musi ocenić, czy to przetwarzanie rodzi ryzyko dla praw i wolności podmiotów danych, a jeśli tak to jakie.
DPIA obowiązuje nas z kolei wtedy, gdy planowane operacje przetwarzania z dużym prawdopodobieństwem mogą generować wysokie ryzyko naruszenia praw lub wolności podmiotów danych. Taką sytuację może rodzić np. przetwarzanie danych z użyciem nowych technologii, więc jak najbardziej wymóg DPIA może pojawić się w startupie.
Cykl Deminga a zarządzanie ryzykiem przetwarzania danych
Tym, co łączy ogólną analizę ryzyka z DPIA jest konieczność ich ponawiania. Nie są to jednorazowe czynności, bo ogólna analiza ryzyka powinna być co jakiś czas powtórzona, a DPIA wymaga przeglądu w kontekście zmieniających się okoliczności (np. zmniejszenie/zwiększenie ryzyka). Innymi słowy, RODO stawia nam wymóg monitorowania ryzyka, które nasze czynności przetwarzania mogą stwarzać dla praw lub wolności podmiotów danych.
To powoduje, że analiza ryzyka jest niejako projektem, do którego warto stosować zasady z cyklu Deminga:
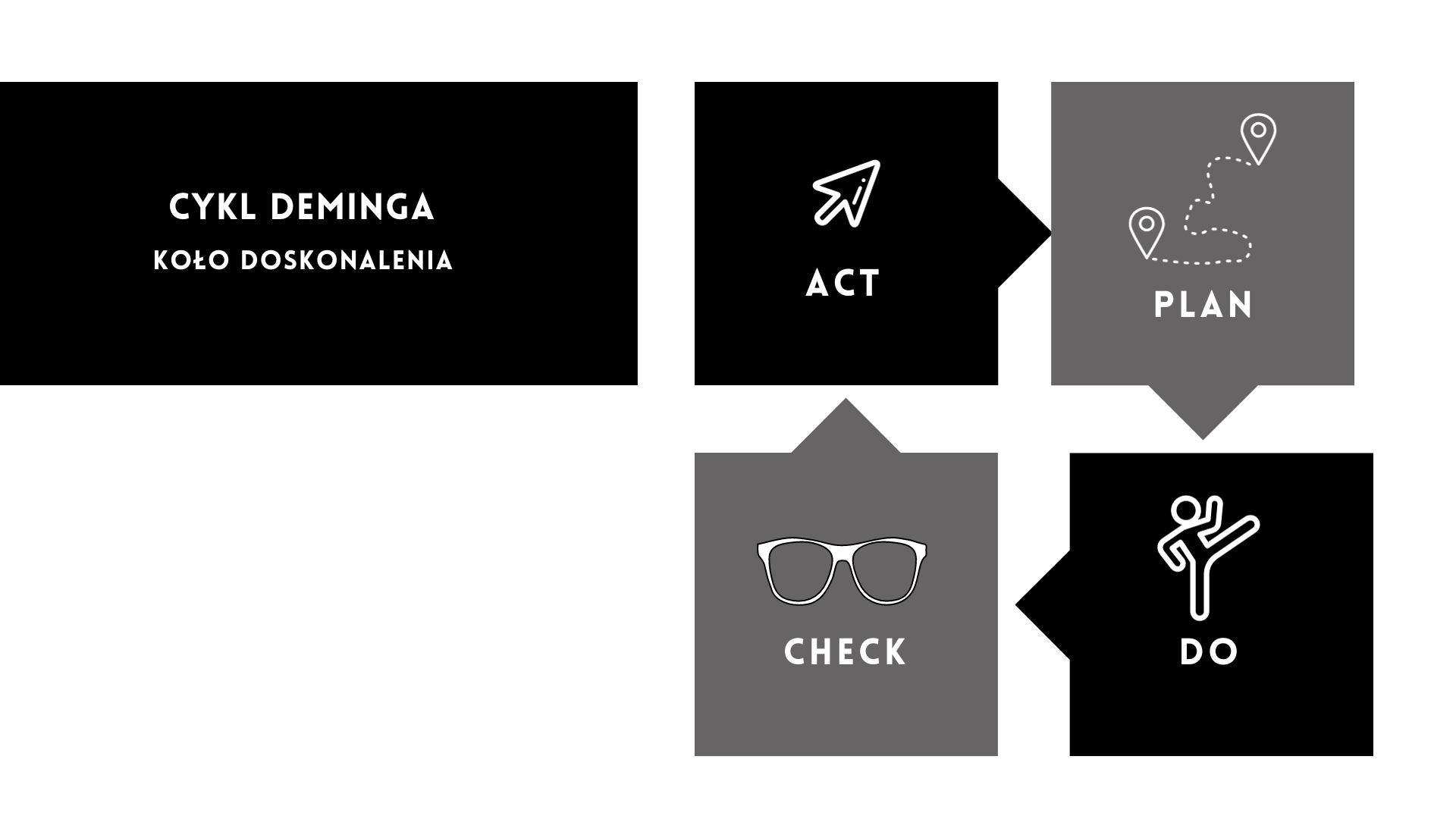
W fazie Planowania musimy zrozumieć kontekst przetwarzania danych i oszacować ryzyko, by opracować plan postępowania z tym ryzykiem.
W fazie Wykonania wdrażamy plan postępowania z ryzykiem.
Później, w fazie Sprawdzania, monitorujemy czy wykonywane działania są skuteczne. Jeśli są, w fazie Poprawy wprowadzamy je jako standard albo - jeśli są nie w pełni skuteczne - przystępujemy do doskonalenia.
Można w uproszczeniu powiedzieć, że oceniamy ryzyko w trzech zasadniczych celach:
1) żeby zidentyfikować obszary, które wymagają dodatkowej ochrony lub innych środków zaradczych (np. szyfrowanie danych, wprowadzenie bardziej rygorystycznych procedur autoryzacji czy szkolenie pracowników.)
2) żeby zweryfikować, czy nasze środki bezpieczeństwa są NA BIEŻĄCO odpowiednie do poziomu ryzyka
3) żeby wybadać, jakimi środkami wykażemy, że zrealizowaliśmy wymogi RODO w zakresie bezpieczeństwa danych
Ocena ryzyka w fazie projektowania
Michael Seibel, CEO i partner w Y Combinator powiedział kiedyś, że "Startupy to eksperymenty przekształcające się w firmy."
Wszystko co dzieje się w startupie jest początkiem czegoś niepewnego. Nie wiemy, jaki ostateczny kształt biznesowy przyjmie MVP. Taką sytuację, w kontekście ochrony danych osobowych, najlepiej adresuje jeden z przepisów RODO - art. 25, który dotyczy oceny ryzyka w fazie projektowania.
Przepis ten skupia naszą uwagę na początkowej fazie planowania przetwarzania danych osobowych i jest odzwierciedleniem koncepcji privacy by design, której temat obiecałam pogłębić w poprzednim odcinku tego rozdziału handbooka.
Privacy by design jest koncepcją wypracowaną przez Anne Cavoukian. Pani Cavoukian była w latach 90. XX w. Komisarzem ds. Ochrony Danych w Ontario. Przekonania do których doszła zostały wdrożone w Rezolucji pn. AEPD, czyli „A Guide to Privacy by Design”. Znajdujemy tam podstawowe zasady ochrony prywatności w fazie projektowania, którymi są:
- działania proaktywne, nie reaktywne (zapobiegamy zamiast naprawiać)
- prywatność jako ustawienie domyślne (np. tworzymy bariery dla łączenia niezależnych źródeł danych)
- prywatność osadzona w projekcie (w całym cyklu życia usługi)
- pełna funkcjonalność: suma dodatnia, a nie zero - jest to wskazówka, że jeżeli pomysł zagraża prywatności, szukamy alternatyw, dzięki którym zaproponujemy zamierzone funkcje, bez uszczerbku na bezpieczeństwie
- kompleksowe zabezpieczenia - np. gwarancja retencji danych
- widoczność i przejrzystość - np. łatwy dostęp do danych udzielony osobom, których dane dotyczą
- poszanowanie prywatności użytkowników
W zasadzie privacy by design mamy też wpisaną komplementarną do niej zasadę - tzw. zasadę privacy by default, która dotyczy ustawień np. aplikacji mobilnej na moment, w którym użytkownik podłączy się do niej po raz pierwszy. Jej zastosowanie przejawia się w tym, że:
- przetwarzamy w aplikacji tylko tyle danych, ile jest niezbędne i minimalne, żeby osiągnąć cel
- liczba operacji przetwarzania jest ograniczona do minimum pozwalającego na osiągnięcie celu
- retencja danych skrócona do minimum - dane są usuwane w chwili osiągnięcia celu
- liczba osób, którym udostępnia się dane jest ograniczona do minimum.
Zgodnie z privacy by default użytkownik nie musi przeklikać apki, żeby działała według ww. założeń, bo administrator ma obowiązek niejako wbudować w aplikację taką minimalistyczną filozofię postępowania z danymi osobowymi. Jak to świetnie ujął dr Wojciech R.Wiewiórkowski „zasada privacy by design oznacza, że bierny użytkownik nie staje się ofiarą swojej bierności, a beneficjentem ustawień domyślnych systemu”.
Dla startupów zasada privacy by design jest kluczowa. W fazie projektowania łatwiej jest uwzględnić aspekty związane z ochroną danych, niż próbować dostosować istniejące rozwiązania w późniejszym czasie. Dzięki temu startup jest bardziej elastyczny i gotowy do skalowania swojego produktu czy usługi bez obaw o naruszenie przepisów o ochronie danych. Ponadto, wczesne uwzględnienie ochrony danych może ułatwić integrację z innymi standardami branżowymi czy technologicznymi, które startup może chcieć wdrożyć w przyszłości.
Startupowe case study
Powiedzmy, że mamy startup z branży healthtech, który rozwija w swoim produkcie funkcję, pozwalającą placówkom medycznym umawiać wizyty 24h na dobę i automatycznie autoryzować uprawnienia pacjentów.
Spróbujmy ocenić ryzyko dla przetwarzania danych związane z działaniem takiej funkcji chatbota umawiającego wizyty lekarskie w aplikacji do monitorowania stanu zdrowia.
Celem przetwarzania jest rezerwacja wizyty za pomocą chatbota działającego w aplikacji. Rezerwacji, a co za tym idzie pozostawienia swoich danych, będą dokonywali pacjenci danej sieci medycznej (którzy postanowią „przenieść się” z infolinii rejestracyjnej na apkę) oraz osoby niebędące dotąd pacjentami sieci.
Jakie dane będą zostawiać „starzy” i „nowi pacjenci”?
Najpewniej, w uproszczonej liczbie, będą to:
- imię i nazwisko,
- nick z aplikacji,
- numer PESEL
- numer telefonu
- lokalizacja
- wybór usługi medycznej i termin wizyty,
- opcjonalną wiadomość dla lekarza,
- numer ID nadany przez chatbota, treść konwersacji, data i godzina rozmowy.
- rekord akceptacji regulaminu usługi
Te dane, w różnym niezbędnym zakresie, będą przetwarzane, np:
- zabierane na etapie rejestracji rozmowy w chatbocie
- zapisywane na etapie potwierdzenia akceptacji regulaminu przez użytkownika,
- przesyłane przy weryfikacji zgodności danych z CRM placówki medycznej, itd.
Wyobraźmy sobie, co się może złego z tymi danymi stać w toku ich przetwarzania.
Może nastąpić ich skompromitowanie, tzn. naruszenie poufności, np. sytuacja, w której osoba nieuprawniona będzie miała dostęp do tych danych. Prawdopodobieństwo wystąpienia tego zagrożenia jest bez wątpienia niskie, ale co ze skutkami wystąpienia tego zagrożenia? Jeżeli ktoś dowie się, że użytkownik A w dniu 13.10 zapisał się do lekarza rodzinnego ws. kataru - nikomu nie wyrządzi to krzywdy. Ale jeżeli ktoś dowie się, że użytkownik B w tym samym dniu zapisał się do psychiatry, zostawiając opcjonalną wiadomość dla lekarza pt. „Potrzebuję iść na chorobowe i leków, nie chce mi się żyć, mam depresję, żona chce się rozwieść” …tu zaczynają się schody, bo ryzyko naruszenia praw lub wolności podmiotu jest już umiarkowane lub wysokie, a nie niskie.
Środki techniczne, organizacyjne i mechanizmy bezpieczeństwa powinny zatem być zaostrzone. Nie wystarczą tutaj standardowe polityki i procedury bezpieczeństwa, fizyczne zabezpieczenia dostępu do infrastruktury chmury czy szyfrowanie połączeń - konieczne byłoby wbudowanie pseudonimizacja.
Może nastąpić również naruszenie integralności danych - np. błędne przypisanie wizyty, w efekcie czego pacjent, który miał trafić do dentysty, trafi do reumatologa. Ryzyko naruszenia praw lub wolności podmiotu danych jest tutaj niskie - naruszenie integralności danych przyczyni się do straty czasu pacjenta, ale nie będzie stanowić większego zagrożenia.
Co z naruszeniem dostępności danych? Przecież dane mogą zostać utracone, w efekcie czego użytkownik straci historię wizyt i informacje o przyszłych rezerwacjach. Ryzyko naruszenia praw lub wolności jest tu nadal niskie - utrata danych spowoduje jedynie rozdrażnienie.
W zależności od poziomu ryzyka wdrażamy odpowiednie środki bezpieczeństwa. Jeżeli nie stwierdzamy wysokiego ryzyka, nie jesteśmy zobowiązani do dokonania DPIA.
Cdn..